kafka
kafka
Kafka Topics
topics: a particular stream of data
basic
- 没有数量限制
- name 作为 id
- 支持所有 format: json, binary, text…
- data 默认保存一周
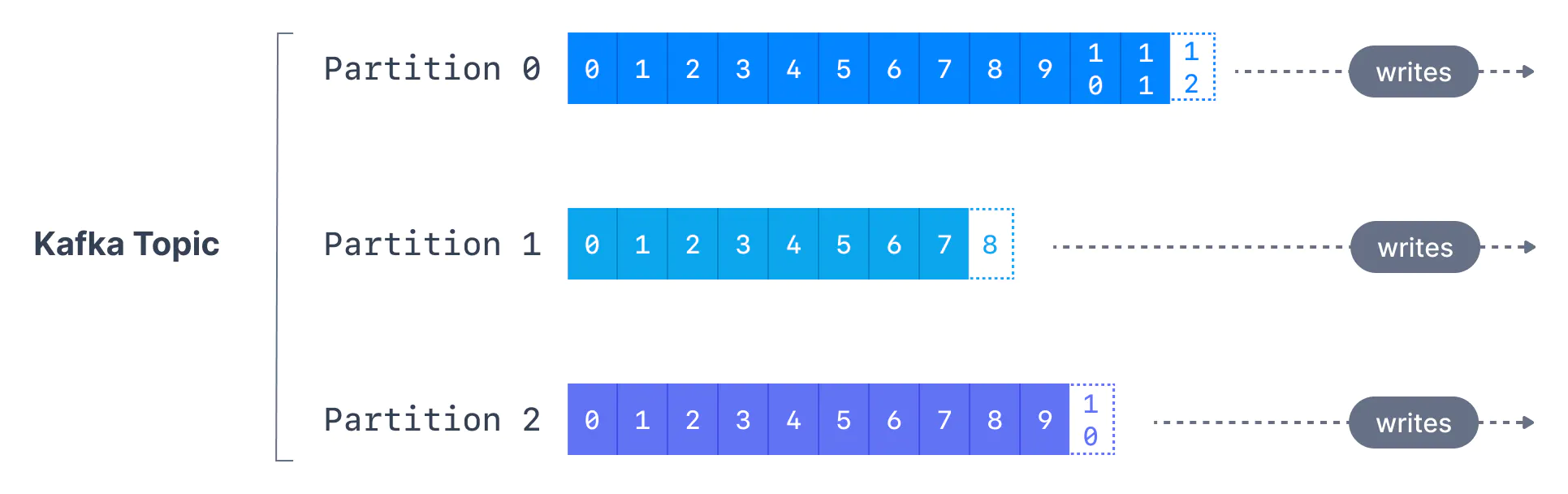
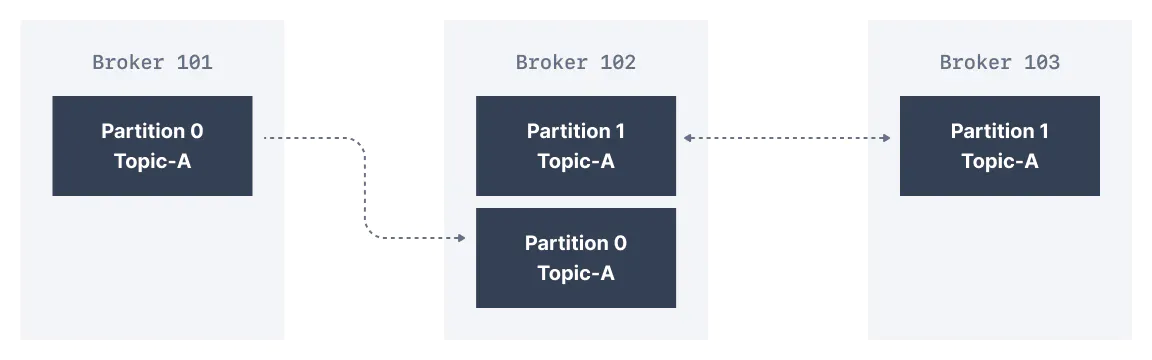
partition and offsets
- topics are split in partitions
- 每个 partition 内部是 ordered 的
- 每个 message 在 partition 内部有一个自增的 id, 也叫做 offset
- message 被发送后不可再更改 immutable
- message 默认情况下会被随机发送给一个 partition, 除非提供一个 key
Producers
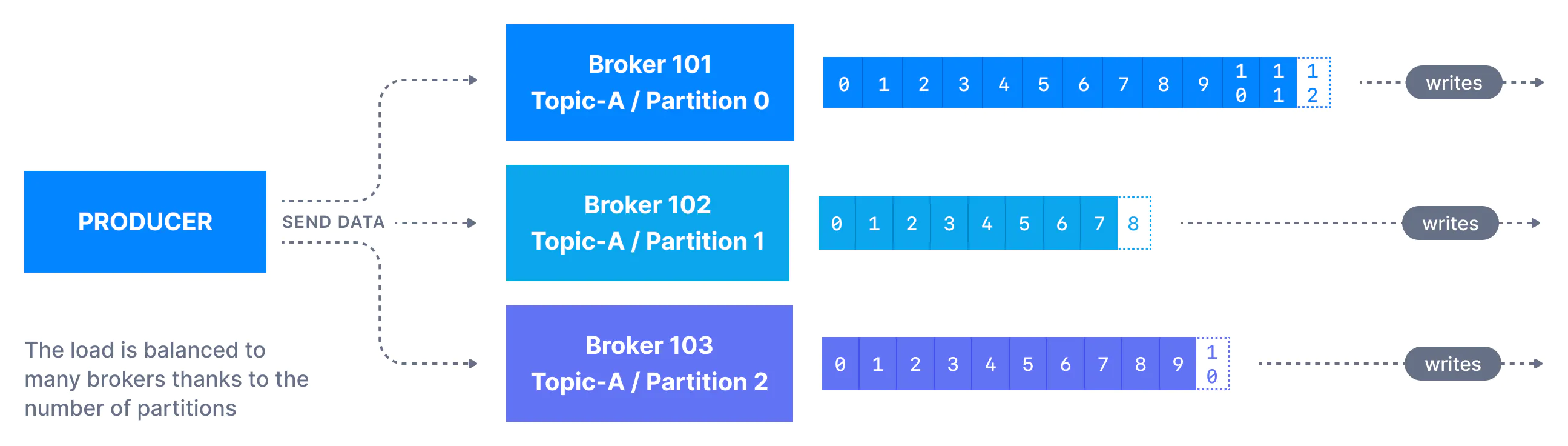
write data to topics
Producers: Message keys
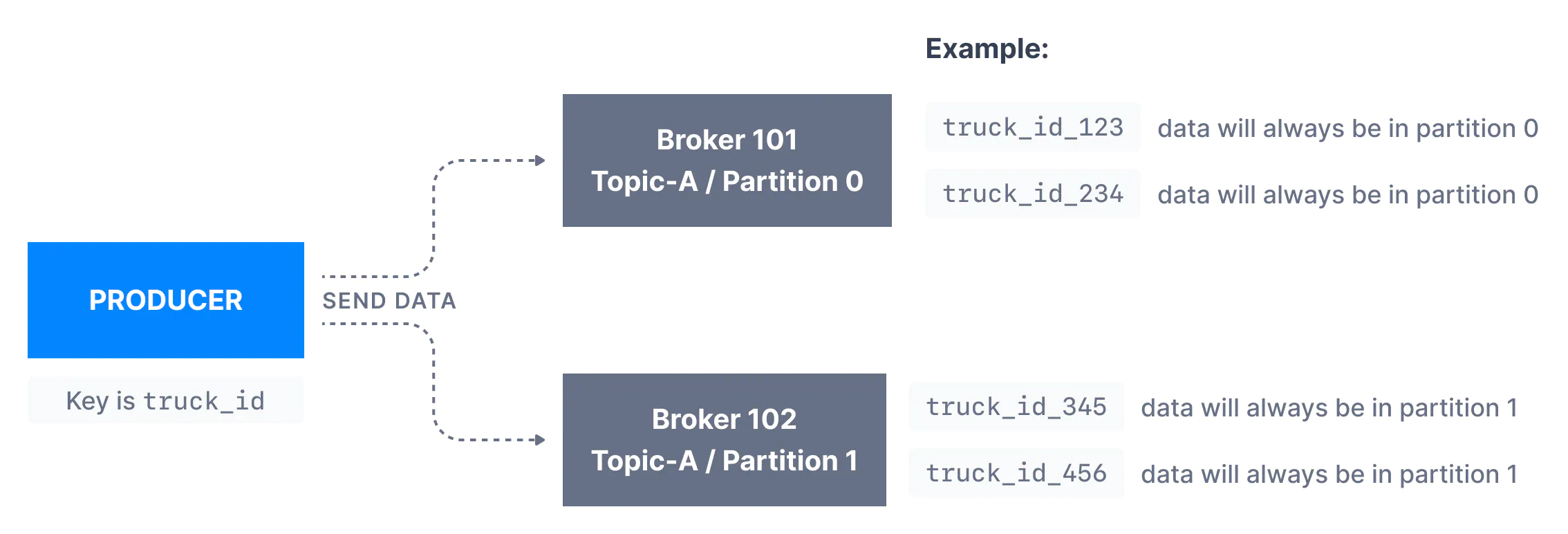
- 如果没有 key, message 发送按照 round robin (partition 0 -> 1 -> 2, 按照 partition 的顺序依次发送)
- 如果有 key, 相同 key 的 message 会被发送到同一个 partition (使用 hashing)
- 如果需要 message ordered, 通常需要给 message 添加 id
Message
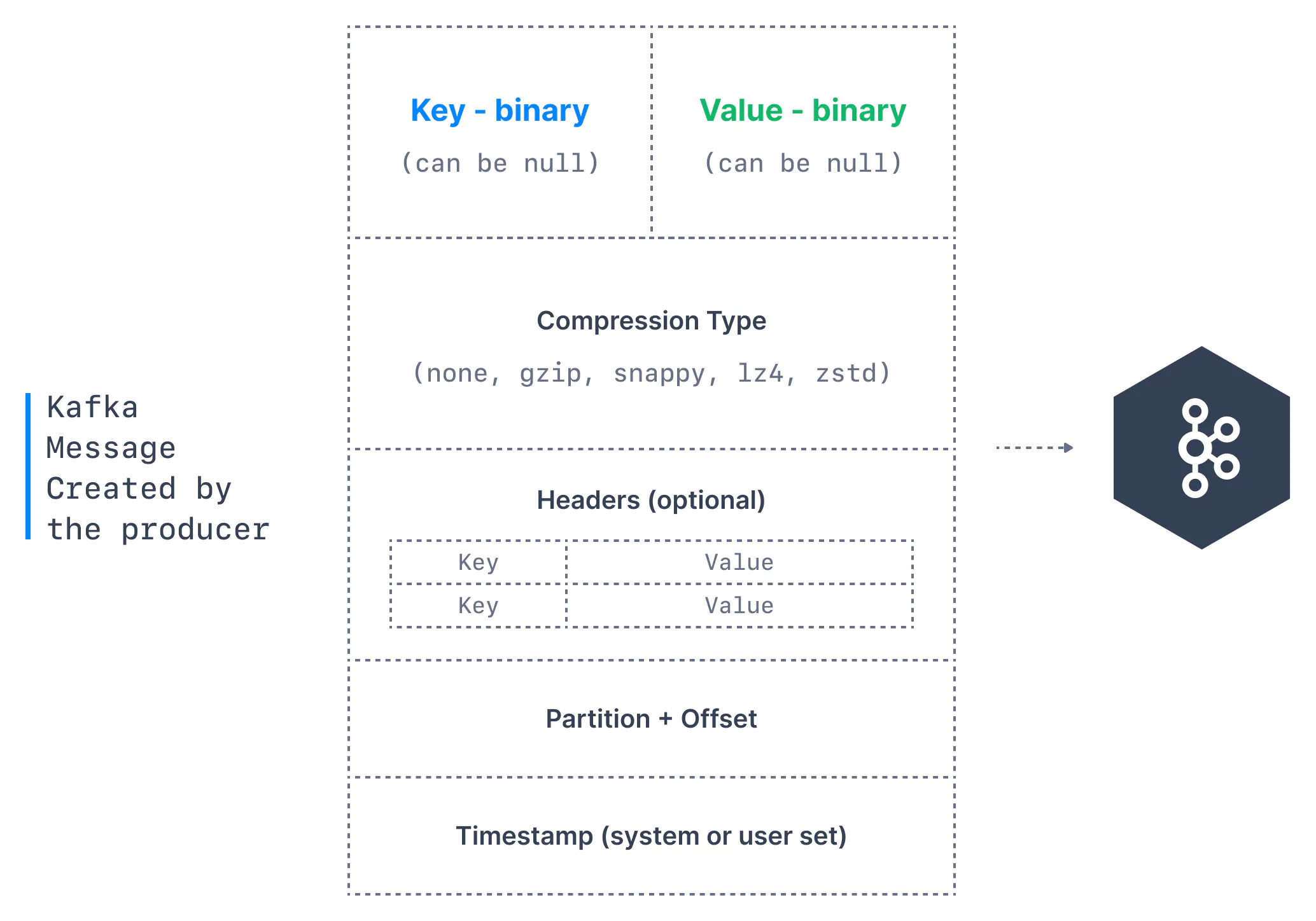
producers acks
- acks=0: producers won’t wait for acknowledgment (possible data loss)
- acks=1: producers will wait for leader acknowledgement (limited data loss)
- acks=all: producers will wait for leader and replicas acknowledgement (no data loss)
Consumers
read data from a topic - pull model
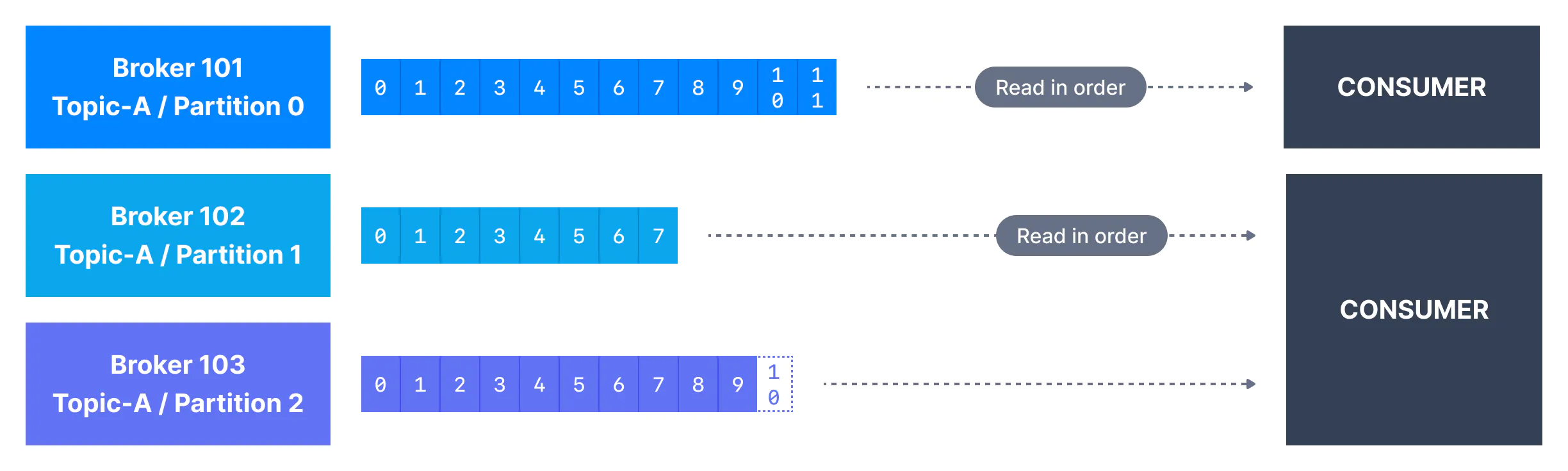
Consumer Groups & Offsets
all consumers read data as a consumer groups
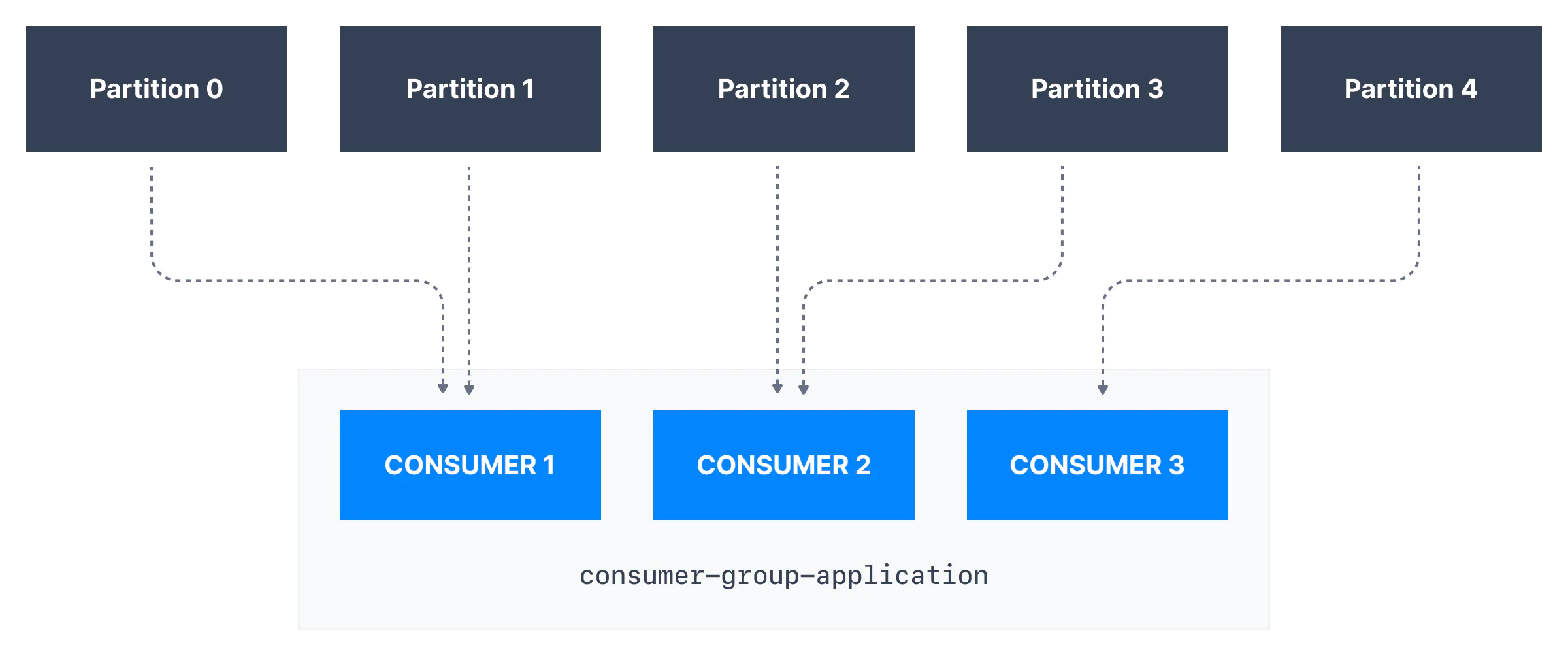
Multiple Consumers on One Topic
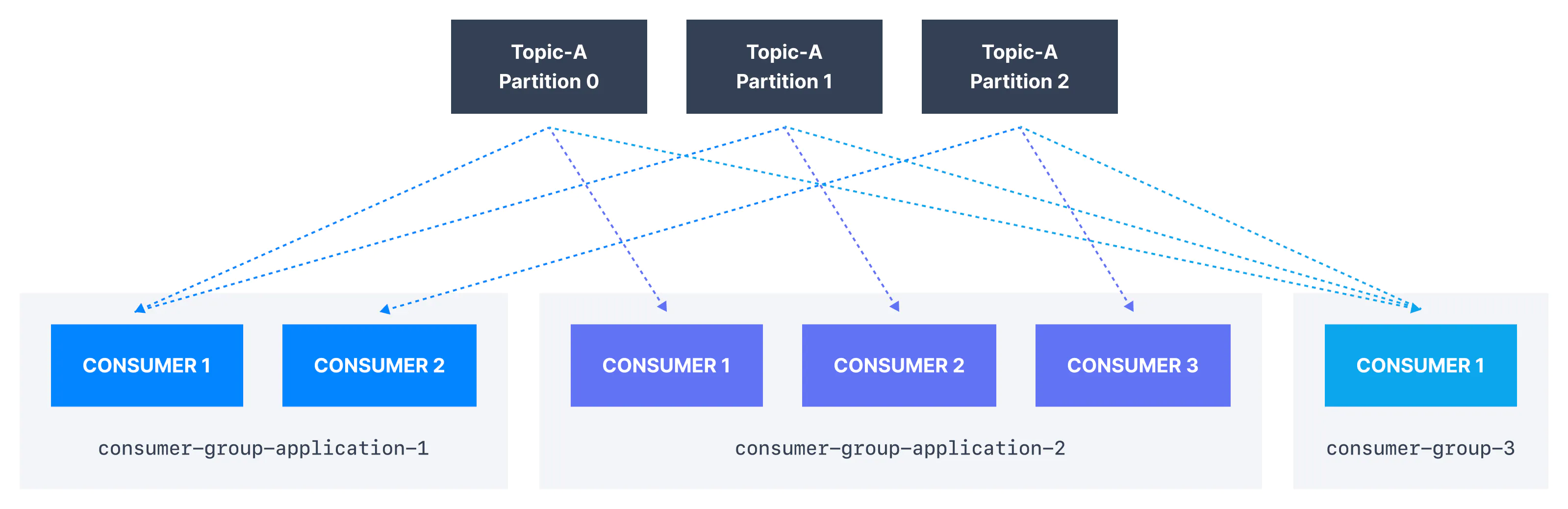
- one topic can have multiple consumer groups
- 每个 consumer group 得到全部 messages
Kafka Brokers
a kafka cluster is composed of multiple brokers (servers)
- each broker identified by ID
- each broker contains certain topic partitions
- data is distributed
- connect to one broker = connect to whole cluster
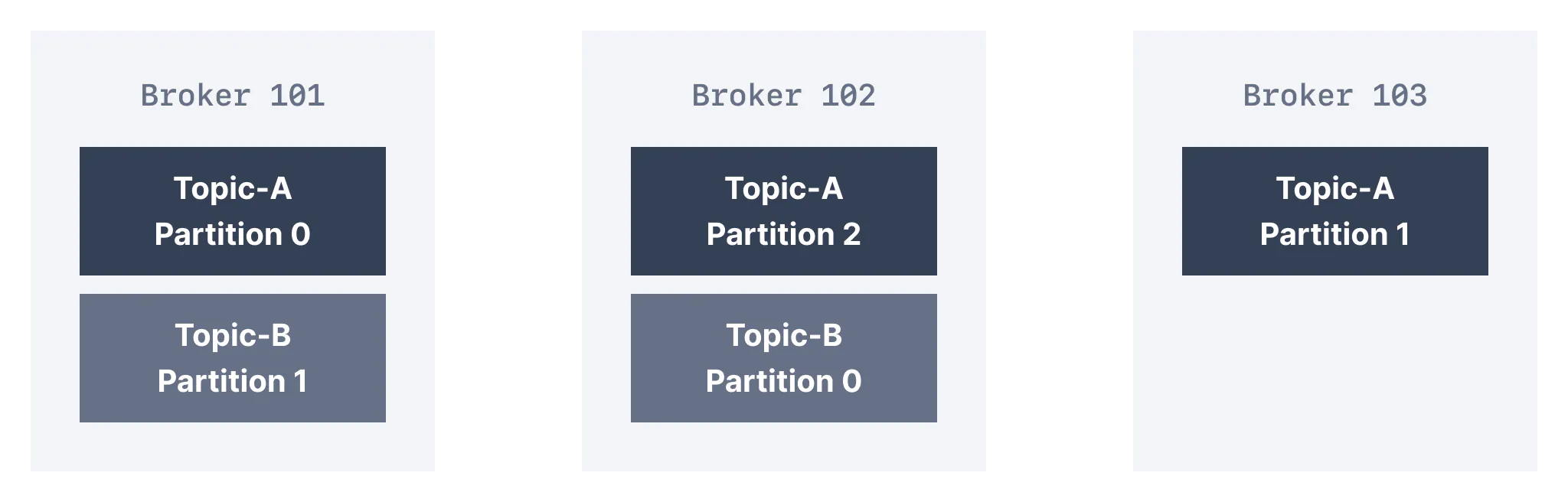
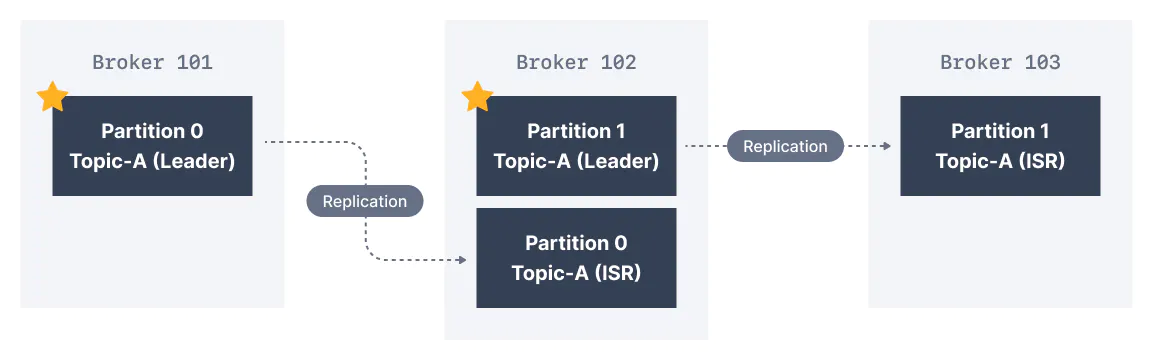
Kafka Topic Replication
replication means that data is written down not just to one broker
Leader for a Partition
- only one broker can be a leader for a partition
- producer can only send data to leader
- consumer read data from leader by default
- other brokers will have replication data
- each partition has one leader and many ISR (in-sync replica)
Demo Code
Producer
package io.conduktor.demos.kafka.wikimedia;
import com.launchdarkly.eventsource.EventHandler;
import com.launchdarkly.eventsource.EventSource;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import java.net.URI;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class WikimediaChangesProducer {
public static void main(String[] args) throws InterruptedException {
String bootstrapServers = "127.0.0.1:9092";
// create producer properties
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// set safe producer for kafka version <= 2.8
// properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
// properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
// properties.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
// set high throughput producer configs
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20"); // 20ms
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32 * 1024)); //32kb
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); // compression method
// create producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
String topic = "wikimedia.recentchange";
EventHandler eventHandler = new WikimediaChangeHandler(producer, topic);
String url = "https://stream.wikimedia.org/v2/stream/recentchange";
EventSource.Builder builder = new EventSource.Builder(eventHandler, URI.create(url));
EventSource eventSource = builder.build();
// start the producer in another thread
eventSource.start();
// produce 10 mins
TimeUnit.MINUTES.sleep(10);
}
}
package io.conduktor.demos.kafka.wikimedia;
import com.launchdarkly.eventsource.EventHandler;
import com.launchdarkly.eventsource.MessageEvent;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WikimediaChangeHandler implements EventHandler {
KafkaProducer<String, String> kafkaProducer;
String topic;
private final Logger log = LoggerFactory.getLogger(WikimediaChangeHandler.class.getSimpleName());
public WikimediaChangeHandler(KafkaProducer<String, String> kafkaProducer, String topic) {
this.kafkaProducer = kafkaProducer;
this.topic = topic;
}
@Override
public void onOpen() {
}
@Override
public void onClosed() {
kafkaProducer.close();
}
@Override
public void onMessage(String event, MessageEvent messageEvent) {
log.info(messageEvent.getData());
// receive and send message async
kafkaProducer.send(new ProducerRecord<>(topic, messageEvent.getData()));
}
@Override
public void onComment(String comment) {
}
@Override
public void onError(Throwable t) {
log.error("error", t);
}
}
Consumer
package io.conduktor.demos.kafka.opensearch;
import com.google.gson.JsonParser;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.DefaultConnectionKeepAliveStrategy;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.opensearch.action.bulk.BulkRequest;
import org.opensearch.action.bulk.BulkResponse;
import org.opensearch.action.index.IndexRequest;
import org.opensearch.action.index.IndexResponse;
import org.opensearch.client.RequestOptions;
import org.opensearch.client.RestClient;
import org.opensearch.client.RestHighLevelClient;
import org.opensearch.client.indices.CreateIndexRequest;
import org.opensearch.client.indices.GetIndexRequest;
import org.opensearch.common.xcontent.XContentType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.net.URI;
import java.time.Duration;
import java.util.Collection;
import java.util.Collections;
import java.util.Properties;
public class OpenSearchConsumer {
public static RestHighLevelClient createOpenSearchClient() {
// String connString = "http://localhost:9200"; // local docker setting
// bonsai.io URL
String connString = "https://fake_uri";
// build a URI from the connection string
RestHighLevelClient restHighLevelClient;
URI connUri = URI.create(connString);
// extract login information if it exists
String userInfo = connUri.getUserInfo();
if (userInfo == null) {
// REST client without security
restHighLevelClient = new RestHighLevelClient(RestClient.builder(new HttpHost(connUri.getHost(), connUri.getPort(), "http")));
} else {
// REST client with security
String[] auth = userInfo.split(":");
CredentialsProvider cp = new BasicCredentialsProvider();
cp.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(auth[0], auth[1]));
restHighLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost(connUri.getHost(), connUri.getPort(), connUri.getScheme()))
.setHttpClientConfigCallback(
httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(cp)
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())));
}
return restHighLevelClient;
}
private static KafkaConsumer<String, String> createKafkaConsumer() {
// local kafka endpoint
String bootstrapServer = "127.0.0.1:9092";
String groupId = "consumer-opensearch-demo";
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServer);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// commit offset manually instead of automatically
// consumer.commitSync(); is required if it is false
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// create consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
return consumer;
}
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(OpenSearchConsumer.class.getSimpleName());
// first create opensearch client
RestHighLevelClient openSearchClient = createOpenSearchClient();
// create kafka client
KafkaConsumer<String, String> consumer = createKafkaConsumer();
// create index on opensearch if it does not exist
try (openSearchClient; consumer) {
boolean indexExist = openSearchClient.indices().exists(new GetIndexRequest("wikimedia"), RequestOptions.DEFAULT);
if (!indexExist) {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("wikimedia");
openSearchClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
} else {
logger.info("wikimedia exists");
}
// check on bonsai GET /wikimedia/_doc/hVsBJ4QBR2gbmWKcd1Th
consumer.subscribe(Collections.singleton("wikimedia.recentchange"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000));
int recordCount = records.count();
logger.info("receive" + recordCount);
// bulk request improve performance
BulkRequest bulkRequest = new BulkRequest();
for (ConsumerRecord<String, String> record : records) {
// id can be this if data does not have id
// String id = record.topic() + "_" + record.partition() + "_" + record.offset();
try {
String id = extractId(record.value());
// send record to opensearch
IndexRequest indexRequest = new IndexRequest("wikimedia")
.source(record.value(), XContentType.JSON)
.id(id); // at least once strategy
// single request - not good performance
// IndexResponse response = openSearchClient.index(indexRequest, RequestOptions.DEFAULT);
// bulk request - good performance
bulkRequest.add(indexRequest);
} catch (Exception e) {
e.printStackTrace();
}
}
// bulk request to improve performance
if (bulkRequest.numberOfActions() > 0) {
BulkResponse bulkResponse = openSearchClient.bulk(bulkRequest, RequestOptions.DEFAULT);
logger.info("inserted" + bulkResponse.getItems().length);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// this is required if ENABLE_AUTO_COMMIT_CONFIG is flase
consumer.commitSync();
logger.info("offsets committed!");
}
}
}
}
private static String extractId(String json) {
return JsonParser.parseString(json).getAsJsonObject().get("meta").getAsJsonObject().get("id").getAsString();
}
}
Advanced Topics
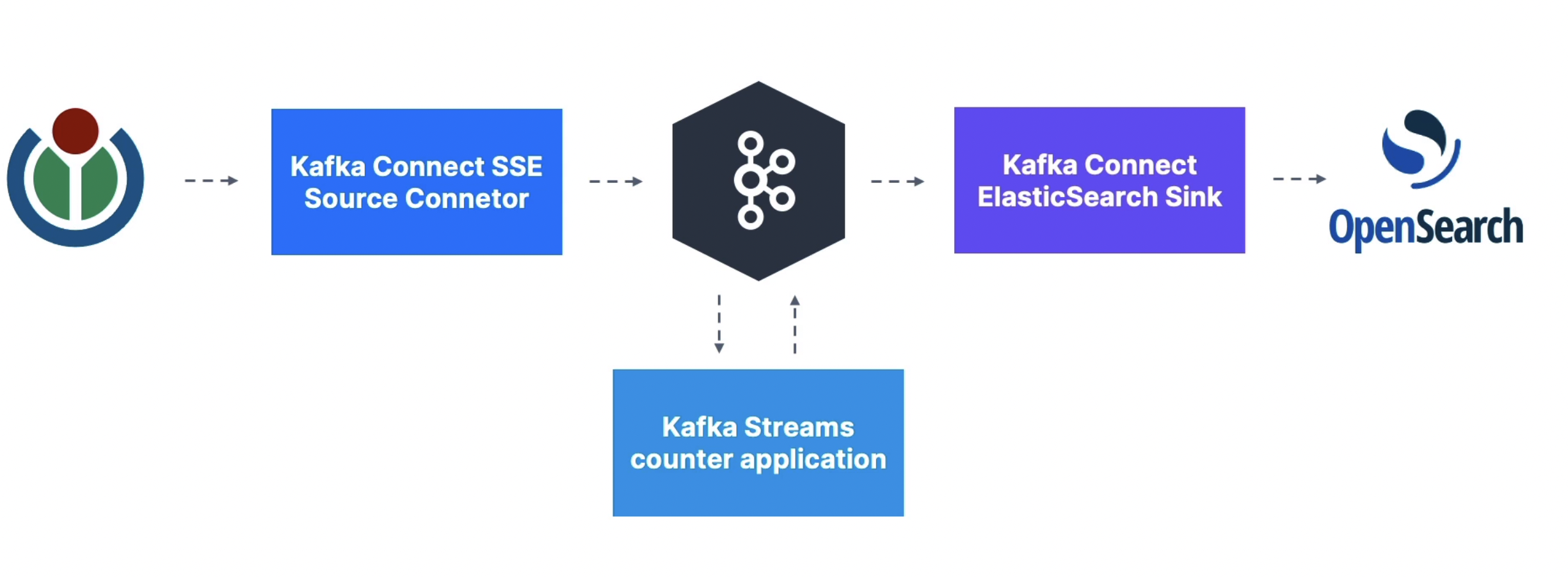
Kafka Connect - connector
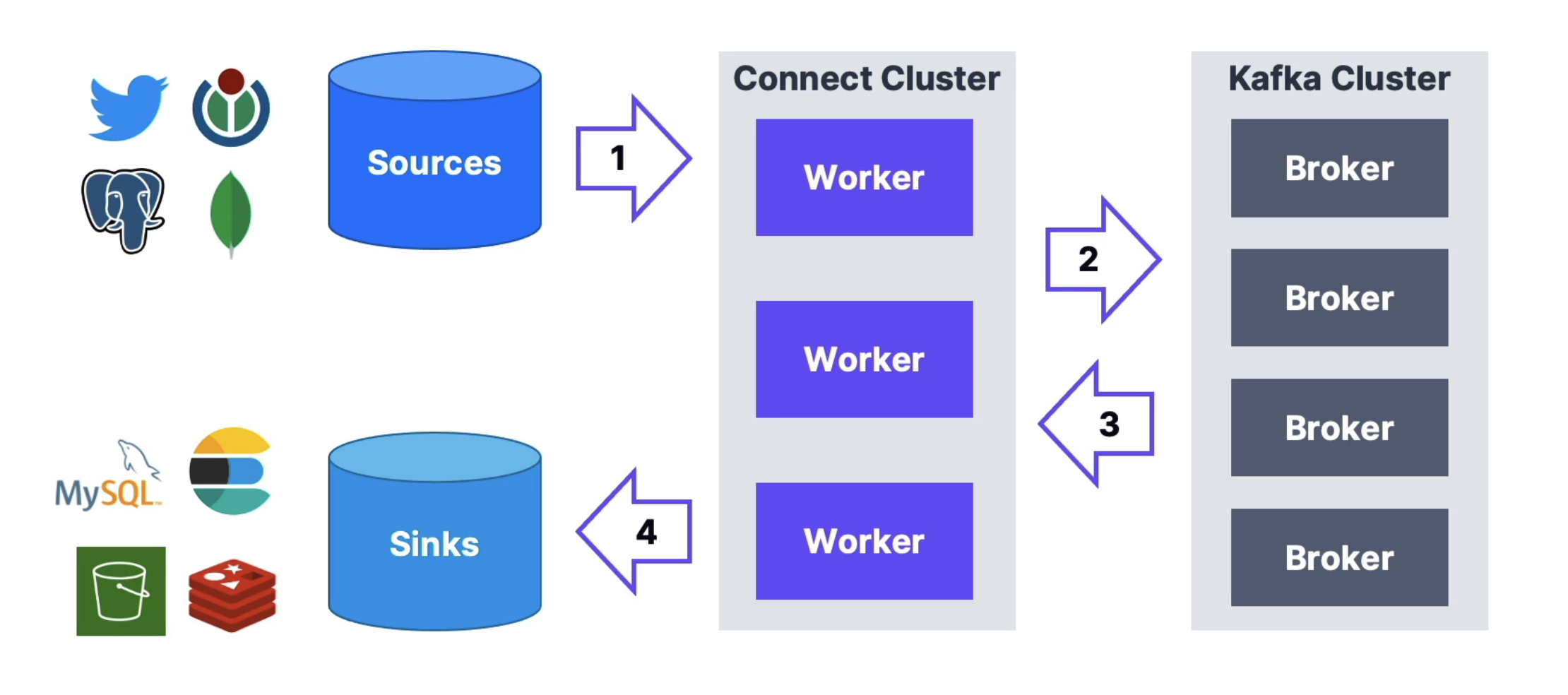
Kafka Connect is all about code & connectors re-use! like get/push data to Database
Kafka Stream
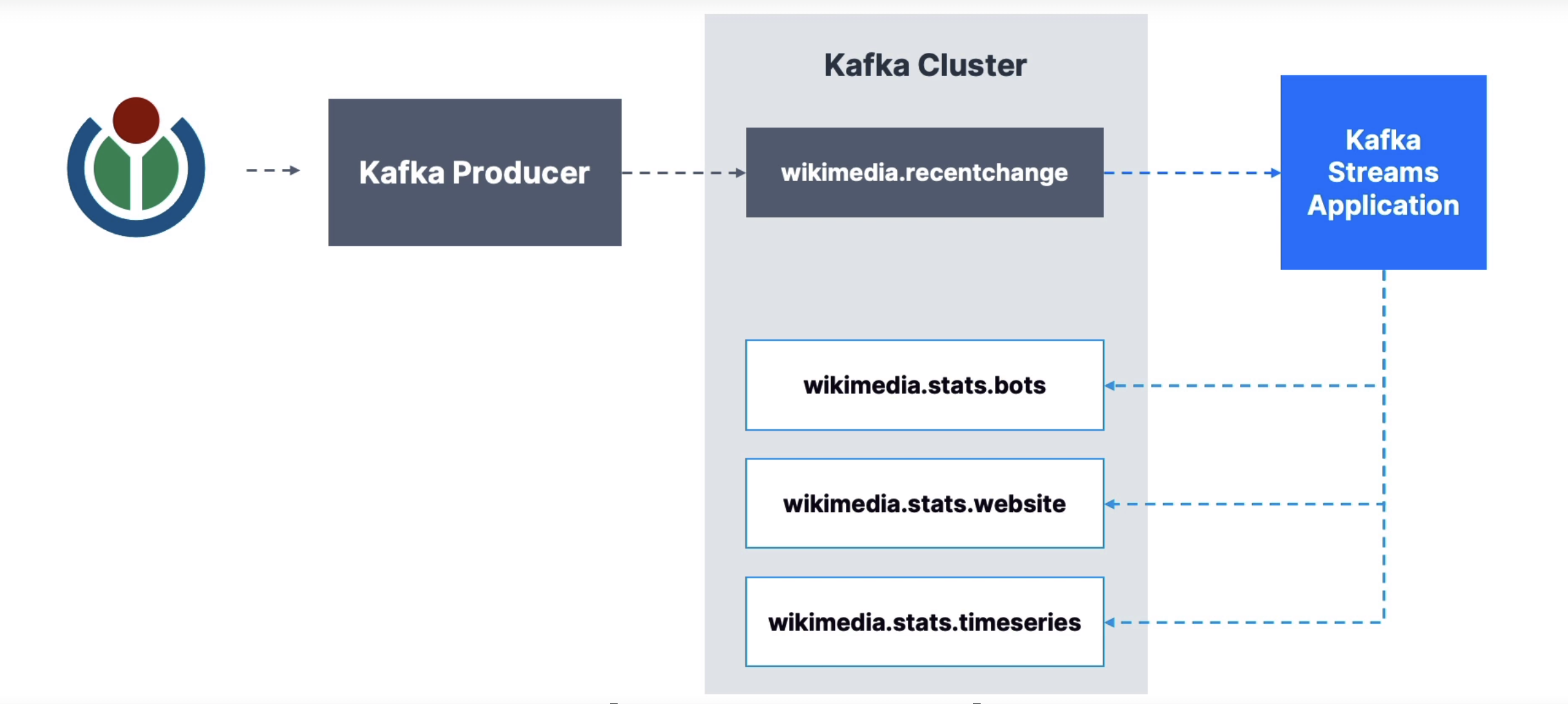
Easy data processing and transformation library within Kafka
Kafka Schema Registry
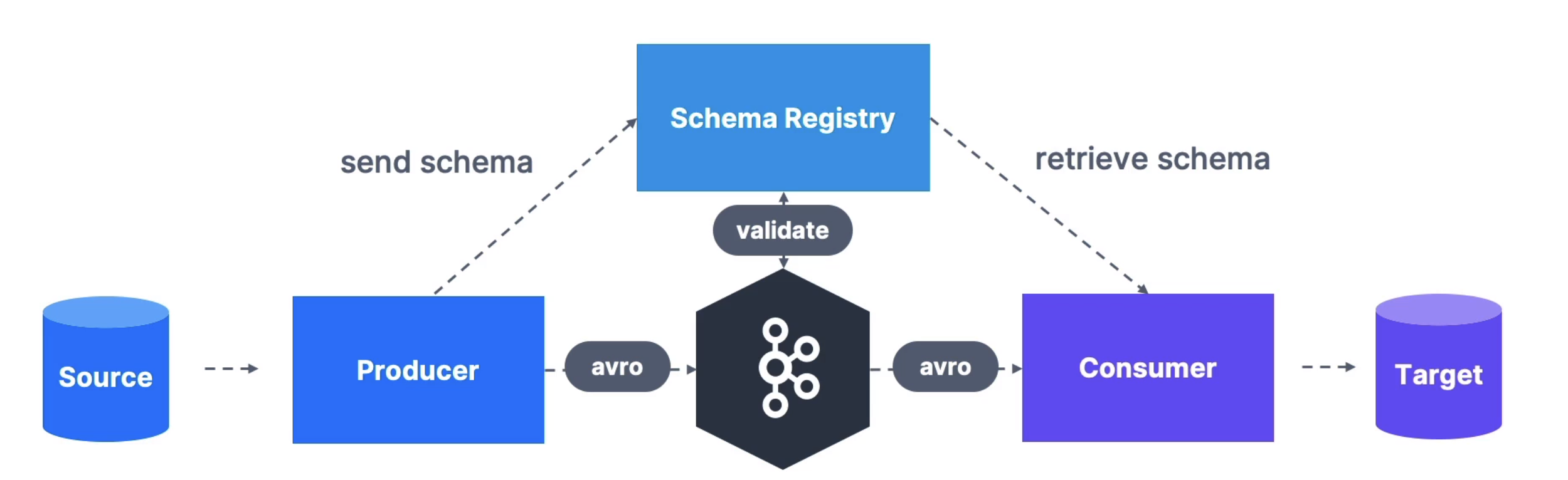
Schema Registry can reject bad data
Real World Practice
Partition Count
- More partitions
- better parallelism - good
- better throughput - good
- can run more consumers - good
- can run more brokers - good
- worse Zookeeper performance - bad
- more files opened on Kafka - bad
- small cluster (< 6 brokers): use 3 * brokers partitions
- big cluster (> 12 brokers): use 2 * brokers partitions
- adjust based on throughput
Replication Factor
- 2 <= replication factor <= 4
- High replication factor
- better durability - good
- better availability - good
- higher latency - bad
- more disk space - bad
- set 3 as start
- never set 1 in production